Learning State Importance for Preference-based Reinforcement Learning
Introduction
Preference-based reinforcement learning (PbRL) leverages human preferences for reinforcement learning (RL) agents. In this setting, human annotators provides their preferences over trajectories, and an agent learns a reward function from these preferences. This setting is useful for human-in-the-loop applications, or when there lacks a reward function.
Apart from empirical performance, interpretability is also a first principle. Interpretability is crucial for users to develop understanding and trust in agents. It is even mandatory for next-generation ethical AI. In April 2021, the European Commission released a new proposal for regulating AI systems, which prescribes obligatory guarantee for transparency in high-risk systems. Moreover, it also allows for debugging PbRL agents more efficiently.
However, current PbRL methods learn blackbox reward functions that are hardly interpretable. In particular, there lacks a systemactic approach for selecting samples from training data for sample-based explanations, or for constructing explanations using other interpretability approaches.
Approach
A framework is proposed to learn a reward function and a weighting network for states jointly from human preferences. It is assumed that in a long state-action sequences, only a few states are critical to preferences. The two figures below consist of states for the game BeamRider, in which the agent needs to fight with enemy spacecrafts. The left three are examples of critical states, in which an enemy spaceships appears (circled in blue). The right three are examples of non-critical states, in which the agent is flying in open space.
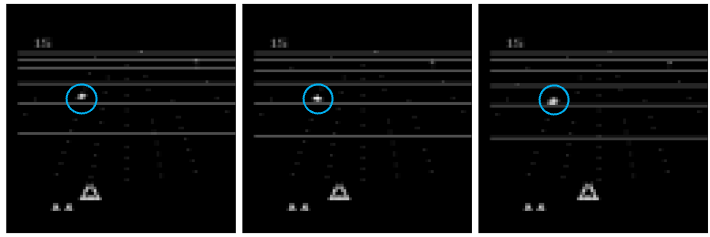

The proposed framework learns to identify critical states by regularizing the output of the weighting network. See our paper for details.
Moreover, this study also proposes a perturbation analysis for evaluating how important the identified states are. The idea is to train behavioral cloning agents on what remains after removing the identified states. The larger performance drops, the more important the removed states are.