Publications
Preprints
2026
-
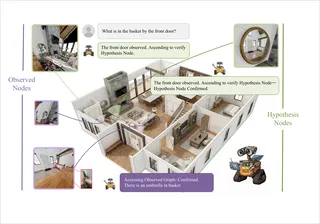 Hypothesis Graph Refinement: Hypothesis-Driven Exploration with Cascade Error Correction for Embodied NavigationPeixin Chen, Guoxi Zhang, Jianwei Ma, and Qing LiArxiv, 2026
Hypothesis Graph Refinement: Hypothesis-Driven Exploration with Cascade Error Correction for Embodied NavigationPeixin Chen, Guoxi Zhang, Jianwei Ma, and Qing LiArxiv, 2026Embodied agents must explore partially observed environments while maintaining reliable long-horizon memory. Existing graph-based navigation systems improve scalability, but they often treat unexplored regions as semantically unknown, leading to inefficient frontier search. Although vision-language models (VLMs) can predict frontier semantics, erroneous predictions may be embedded into memory and propagate through downstream inferences, causing structural error accumulation that confidence attenuation alone cannot resolve. These observations call for a framework that can leverage semantic predictions for directed exploration while systematically retracting errors once new evidence contradicts them. We propose Hypothesis Graph Refinement (HGR), a framework that represents frontier predictions as revisable hypothesis nodes in a dependency-aware graph memory. HGR introduces (1) semantic hypothesis module, which estimates context-conditioned semantic distributions over frontiers and ranks exploration targets by goal relevance, travel cost, and uncertainty, and (2) verification-driven cascade correction, which compares on-site observations against predicted semantics and, upon mismatch, retracts the refuted node together with all its downstream dependents. Unlike additive map-building, this allows the graph to contract by pruning erroneous subgraphs, keeping memory reliable throughout long episodes. We evaluate HGR on multimodal lifelong navigation (GOAT-Bench) and embodied question answering (A-EQA, EM-EQA). HGR achieves 72.41% success rate and 56.22% SPL on GOAT-Bench, and shows consistent improvements on both QA benchmarks. Diagnostic analysis reveals that cascade correction eliminates approximately 20% of structurally redundant hypothesis nodes and reduces revisits to erroneous regions by 4.5x, with specular and transparent surfaces accounting for 67% of corrected prediction errors.
@misc{chen2026hgr, title = {Hypothesis Graph Refinement: Hypothesis-Driven Exploration with Cascade Error Correction for Embodied Navigation}, author = {Chen, Peixin and Zhang, Guoxi and Ma, Jianwei and Li, Qing}, year = {2026}, }
Journal Papers
2023
- Learning state importance for preference-based reinforcement learningGuoxi Zhang and Hisashi KashimaMachine Learning, 2023
Preference-based reinforcement learning (PbRL) develops agents using human preferences. Due to its empirical success, it has prospect of benefiting human-centered applications. Meanwhile, previous work on PbRL overlooks interpretability, which is an indispensable element of ethical artificial intelligence (AI). While prior art for explainable AI offers some machinery, there lacks an approach to select samples to construct explanations. This becomes an issue for PbRL, as transitions relevant to task solving are often outnumbered by irrelevant ones. Thus, ad-hoc sample selection undermines the credibility of explanations. The present study proposes a framework for learning reward functions and state importance from preferences simultaneously. It offers a systematic approach for selecting samples when constructing explanations. Moreover, the present study proposes a perturbation analysis to evaluate the learned state importance quantitatively. Through experiments on discrete and continuous control tasks, the present study demonstrates the proposed framework’s efficacy for providing interpretability without sacrificing task performance.
@article{state_imp, author = {Zhang, Guoxi and Kashima, Hisashi}, doi = {10.1007/s10994-022-06295-5}, id = {Zhang2023}, isbn = {1573-0565}, journal = {Machine Learning}, title = {Learning state importance for preference-based reinforcement learning}, year = {2023}, }
2022
- Machine Learning in Materials Chemistry: An InvitationDaniel Packwood, Linh Thi Hoai Nguyen, Pierluigi Cesana, Guoxi Zhang, Aleksandar Staykov, Yasuhide Fukumoto, and Dinh Hoa NguyenMachine Learning with Applications, 2022
Materials chemistry is being profoundly influenced by the uptake of machine learning methodologies. Machine learning techniques, in combination with established techniques from computational physics, promise to accelerate the discovery of new materials by elucidating complex structure–property relationships from massive material databases. Despite exciting possibilities, further methodological developments call for a greater synergism between materials chemists, physicists, and engineers on one side, with computer science and math majors on the other. In this review, we provide a non-exhaustive account of machine learning in materials chemistry for computer scientists and applied mathematicians, with an emphasis on molecule datasets and materials chemistry problems. The first part of this review provides a tutorial on how to prepare such datasets for subsequent model building, with an emphasis on the construction of feature vectors. We also provide a self-contained introduction to density functional theory, a method from computational physics which is widely used to generate datasets and compute response variables. The second part reviews two machine learning methodologies which represent the status quo in materials chemistry at present – kernelized machine learning and Bayesian machine learning – and discusses their application to real datasets. In the third part of the review, we introduce some emerging machine learning techniques which have not been widely adopted by materials scientists and therefore present potential avenues for computer science and applied math majors. In the final concluding section, we discuss some recent machine learning-based approaches to real materials discovery problems and speculate on some promising future directions.
@article{PACKWOOD2022100265, author = {Packwood, Daniel and Nguyen, Linh Thi Hoai and Cesana, Pierluigi and Zhang, Guoxi and Staykov, Aleksandar and Fukumoto, Yasuhide and Nguyen, Dinh Hoa}, journal = {Machine Learning with Applications}, title = {Machine Learning in Materials Chemistry: An Invitation}, volume = {8}, year = {2022}, }
Conference Papers
2026
-
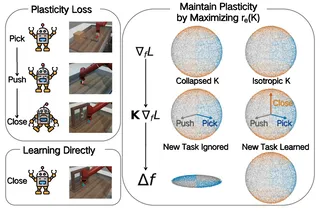 SPHERE: Mitigating the Loss of Spectral Plasticity in Mixture-of-Experts for Deep Reinforcement LearningLirui Luo, Guoxi Zhang, Hongming Xu, Cong Fang, and Qing LiIn Forty-Third International Conference on Machine Learning, 2026
SPHERE: Mitigating the Loss of Spectral Plasticity in Mixture-of-Experts for Deep Reinforcement LearningLirui Luo, Guoxi Zhang, Hongming Xu, Cong Fang, and Qing LiIn Forty-Third International Conference on Machine Learning, 2026In deep reinforcement learning (DRL), an agent is trained from a stream of experience. In a continual learning setting, such agents can suffer from plasticity loss: their ability to learn new skills from new experiences diminishes over training. Recently, Mixture-of-Experts (MoE) networks have been reported to enable scaling laws and facilitate the learning of diverse skills. However, in continual reinforcement learning settings, their performance can degenerate as learning proceeds, indicating a loss of plasticity. To address this, building on Neural Tangent Kernel (NTK) theory, we formalize the plasticity loss in MoE policies as a loss of spectral plasticity. We then derive a tractable proxy for spectral plasticity, one expressible in terms of individual expert feature matrices. Leveraging this proxy, we introduce SPHERE, a practical Parseval penalty tailored for MoE-based policies that alleviates the loss of spectral plasticity. On MetaWorld and HumanoidBench, SPHERE improves average success under continual RL by 133% and 50% over an unregularized MoE baseline, while maintaining higher spectral plasticity throughout training.
@inproceedings{luo2026sphere, title = {SPHERE: Mitigating the Loss of Spectral Plasticity in Mixture-of-Experts for Deep Reinforcement Learning}, author = {Luo, Lirui and Zhang, Guoxi and Xu, Hongming and Fang, Cong and Li, Qing}, booktitle = {Forty-Third International Conference on Machine Learning}, location = {Seoul, South Korea}, year = {2026}, } -
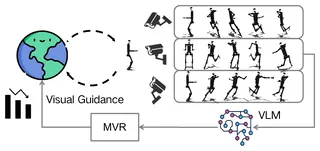 MVR: Multi-view Video Reward Shaping for Reinforcement LearningLirui Luo, Guoxi Zhang, Hongming Xu, Yaodong Yang, Cong Fang, and Qing LiIn The Fourteenth International Conference on Learning Representations, 2026
MVR: Multi-view Video Reward Shaping for Reinforcement LearningLirui Luo, Guoxi Zhang, Hongming Xu, Yaodong Yang, Cong Fang, and Qing LiIn The Fourteenth International Conference on Learning Representations, 2026Reward design is of great importance for solving complex tasks with reinforcement learning. Recent studies have explored using image-text similarity produced by vision-language models (VLMs) to augment rewards of a task with visual feedback. A common practice linearly adds VLM scores to task or success rewards without explicit shaping, potentially altering the optimal policy. Moreover, such approaches, often relying on single static images, struggle with tasks whose desired behavior involves complex, dynamic motions spanning multiple visually different states. Furthermore, single viewpoints can occlude critical aspects of an agent’s behavior. To address these issues, this paper presents Multi-View Video Reward Shaping (MVR), a framework that models the relevance of states regarding the target task using videos captured from multiple viewpoints. MVR leverages video-text similarity from a frozen pre-trained VLM to learn a state relevance function that mitigates the bias towards specific static poses inherent in image-based methods. Additionally, we introduce a state-dependent reward shaping formulation that integrates task-specific rewards and VLM-based guidance, automatically reducing the influence of VLM guidance once the desired motion pattern is achieved. We confirm the efficacy of the proposed framework with extensive experiments on challenging humanoid locomotion tasks from HumanoidBench and manipulation tasks from MetaWorld, verifying the design choices through ablation studies.
@inproceedings{luo2026mvr, title = {MVR: Multi-view Video Reward Shaping for Reinforcement Learning}, author = {Luo, Lirui and Zhang, Guoxi and Xu, Hongming and Yang, Yaodong and Fang, Cong and Li, Qing}, booktitle = {The Fourteenth International Conference on Learning Representations}, location = {Rio de Janeiro, Brazil}, year = {2026}, url = {https://openreview.net/forum?id=7lw6s9ELfr}, }
2025
-
 SYNERGAI: Perception Alignment for Human-Robot CollaborationYixin Chen, Guoxi Zhang, Yaowei Zhang, Hongming Xu, Peiyuan Zhi, Qing Li, and Siyuan HuangIn 2025 IEEE International Conference on Robotics and Automation (ICRA), 2025
SYNERGAI: Perception Alignment for Human-Robot CollaborationYixin Chen, Guoxi Zhang, Yaowei Zhang, Hongming Xu, Peiyuan Zhi, Qing Li, and Siyuan HuangIn 2025 IEEE International Conference on Robotics and Automation (ICRA), 2025Recently, large language models (LLMs) have shown strong potential in facilitating human-robotic interaction and collaboration. However, existing LLM-based systems often overlook the misalignment between human and robot perceptions, which hinders their effective communication and real-world robot deployment. To address this issue, we introduce SYNERGAI, a unified system designed to achieve both perceptual alignment and human-robot collaboration. At its core, SYNERGAI employs 3D Scene Graph (3DSG) as its explicit and innate representation. This enables the system to leverage LLM to break down complex tasks and allocate appropriate tools in intermediate steps to extract relevant information from the 3DSG, modify its structure, or generate responses. Importantly, SYNERGAI incorporates an automatic mechanism that enables perceptual misalignment correction with users by updating its 3DSG with online interaction. SYNERGAI achieves comparable performance with the data-driven models in ScanQA in a zero-shot manner. Through comprehensive experiments across 10 real-world scenes, SYNERGAI demonstrates its effectiveness in establishing common ground with humans, realizing a success rate of 61.9% in alignment tasks. It also significantly improves the success rate from 3.7% to 45.68% on novel tasks by transferring the knowledge acquired during alignment.
@inproceedings{chen2025synergai, title = {SYNERGAI: Perception Alignment for Human-Robot Collaboration}, author = {Chen, Yixin and Zhang, Guoxi and Zhang, Yaowei and Xu, Hongming and Zhi, Peiyuan and Li, Qing and Huang, Siyuan}, booktitle = {2025 IEEE International Conference on Robotics and Automation (ICRA)}, year = {2025}, }
2024
- VickreyFeedback: Cost-Efficient Data Construction for Reinforcement Learning from Human FeedbackGuoxi Zhang and Jiuding DuanIn PRIMA 2024: Principles and Practice of Multi-Agent Systems, 2024
This paper addresses the cost-efficiency aspect of Reinforcement Learning from Human Feedback (RLHF). RLHF leverages datasets of human preferences over outputs of LLMs to instill human expectations into LLMs. While preference annotation comes with a monetized cost, the economic utility of a preference dataset has not been considered by far. What exacerbates this situation is that, given complex intransitive or cyclic relationships in preference datasets, existing algorithms for fine-tuning LLMs are still far from capturing comprehensive preferences. This raises severe cost-efficiency concerns in production environments, where preference data accumulate over time. In this paper, we see the fine-tuning of LLMs as a monetized economy and introduce an auction mechanism to improve the efficiency of the preference data collection in dollar terms. We show that introducing an auction mechanism can play an essential role in enhancing the cost-efficiency of RLHF, while maintaining satisfactory model performance. Experimental results demonstrate that our proposed auction-based protocol is cost-efficient for fine-tuning LLMs by concentrating on high-quality feedback.
@inproceedings{10.1007/978-3-031-77367-9_27, title = {VickreyFeedback: Cost-Efficient Data Construction for Reinforcement Learning from Human Feedback}, author = {Zhang, Guoxi and Duan, Jiuding}, booktitle = {PRIMA 2024: Principles and Practice of Multi-Agent Systems}, pages = {351--366}, year = {2024}, publisher = {Springer Nature Switzerland}, location = {Kyoto, Japan}, url = {https://link.springer.com/chapter/10.1007/978-3-031-77367-9_27#citeas}, } -
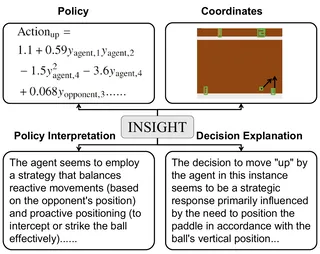 Lirui Luo, Guoxi Zhang, Hongming Xu, Yaodong Yang, Cong Fang, and Qing LiIn Proceedings of the Forty-First International Conference on Machine Learning, 2024
Lirui Luo, Guoxi Zhang, Hongming Xu, Yaodong Yang, Cong Fang, and Qing LiIn Proceedings of the Forty-First International Conference on Machine Learning, 2024Neuro-symbolic reinforcement learning (NS-RL) has emerged as a promising paradigm for explainable decision-making, characterized by the interpretability of symbolic policies. NS-RL entails structured state representations for tasks with visual observations, but previous methods cannot refine the structured states with rewards due to a lack of efficiency. Accessibility also remains an issue, as extensive domain knowledge is required to interpret symbolic policies. In this paper, we present a neuro-symbolic framework for jointly learning structured states and symbolic policies, whose key idea is to distill the vision foundation model into an efficient perception module and refine it during policy learning. Moreover, we design a pipeline to prompt GPT-4 to generate textual explanations for the learned policies and decisions, significantly reducing users’ cognitive load to understand the symbolic policies. We verify the efficacy of our approach on nine Atari tasks and present GPT-generated explanations for policies and decisions.
@inproceedings{pmlr-v235-luo24j, title = {End-to-End Neuro-Symbolic Reinforcement Learning with Textual Explanations}, author = {Luo, Lirui and Zhang, Guoxi and Xu, Hongming and Yang, Yaodong and Fang, Cong and Li, Qing}, booktitle = {Proceedings of the Forty-First International Conference on Machine Learning}, pages = {33533--33557}, year = {2024}, publisher = {PMLR}, location = {Vienna, Austria}, badge = {Spotlight (top 3.5%)} } - Treatment Effect Estimation Under Unknown InterferenceXiaofeng Lin, Guoxi Zhang, Xiaotian Lu, and Hisashi KashimaIn Advances in Knowledge Discovery and Data Mining, 2024
Causal inference is a powerful tool for effective decision-making in various areas, such as medicine and commerce. For example, it allows businesses to determine whether an advertisement has a role in influencing a customer to buy the advertised product. The influence of an advertisement on a particular customer is considered the advertisement’s individual treatment effect (ITE). This study estimates ITE from data in which units are potentially connected. In this case, the outcome for a unit can be influenced by treatments to other units, resulting in inaccurate ITE estimation, a phenomenon known as interference. Existing methods for ITE estimation that address interference rely on knowledge of connections between units. However, these methods are not applicable when this connection information is missing due to privacy concerns, a scenario known as unknown interference. To overcome this limitation, this study proposes a method that designs a graph structure learner, which infers the structure of interference by imposing an L_0-norm regularization on the number of potential connections. The inferred structure is then fed into a graph convolution network to model interference received by units. We carry out extensive experiments on several datasets to verify the effectiveness of the proposed method in addressing unknown interference.
@inproceedings{unknown_interference, author = {Lin, Xiaofeng and Zhang, Guoxi and Lu, Xiaotian and Kashima, Hisashi}, booktitle = {Advances in Knowledge Discovery and Data Mining}, title = {Treatment Effect Estimation Under Unknown Interference}, year = {2024}, }
2023
- Batch Reinforcement Learning from CrowdsGuoxi Zhang and Hisashi KashimaIn Machine Learning and Knowledge Discovery in Databases, 2023
A shortcoming of batch reinforcement learning is its requirement for rewards in data, thus not applicable to tasks without reward functions. Existing settings for the lack of reward, such as behavioral cloning, rely on optimal demonstrations collected from humans. Unfortunately, extensive expertise is required for ensuring optimality, which hinder the acquisition of large-scale data for complex tasks. This paper addresses the lack of reward by learning a reward function from preferences between trajectories. Generating preferences only requires a basic understanding of a task, and it is faster than performing demonstrations. Thus, preferences can be collected at scale from non-expert humans using crowdsourcing. This paper tackles a critical challenge that emerged when collecting data from non-expert humans: the noise in preferences. A novel probabilistic model is proposed for modelling the reliability of labels, which utilizes labels collaboratively. Moreover, the proposed model smooths the estimation with a learned reward function. Evaluation on Atari datasets demonstrates the effectiveness of the proposed model, followed by an ablation study to analyze the relative importance of the proposed ideas.
@inproceedings{crowd_pbrl, author = {Zhang, Guoxi and Kashima, Hisashi}, booktitle = {Machine Learning and Knowledge Discovery in Databases}, location = {Grenoble, France}, pages = {38--51}, publisher = {Springer Cham}, title = {Batch Reinforcement Learning from Crowds}, year = {2023}, } - On Modeling Long-Term User Engagement from Stochastic FeedbackGuoxi Zhang, Xing Yao, and Xuanji XiaoIn Companion Proceedings of the ACM Web Conference 2023, 2023
An ultimate goal of recommender systems (RS) is to improve user engagement. Reinforcement learning (RL) is a promising paradigm for this goal, as it directly optimizes overall performance of sequential recommendation. However, many existing RL-based approaches induce huge computational overhead, because they require not only the recommended items but also all other candidate items to be stored. This paper proposes an efficient alternative that does not require the candidate items. The idea is to model the correlation between user engagement and items directly from data. Moreover, the proposed approach consider randomness in user feedback and termination behavior, which are ubiquitous for RS but rarely discussed in RL-based prior work. With online A/B experiments on real-world RS, we confirm the efficacy of the proposed approach and the importance of modeling the two types of randomness.
@inproceedings{long_term_engagement, author = {Zhang, Guoxi and Yao, Xing and Xiao, Xuanji}, booktitle = {Companion Proceedings of the ACM Web Conference 2023}, location = {Austin, TX, USA}, publisher = {Association for Computing Machinery}, title = {On Modeling Long-Term User Engagement from Stochastic Feedback}, year = {2023}, } - Behavior Estimation from Multi-Source Data for Offline Reinforcement LearningGuoxi Zhang and Hisashi KashimaIn Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence, 2023
Offline reinforcement learning (RL) have received rising interest due to its appealing data efficiency. The present study addresses behavior estimation, a task that lays the foundation of many offline RL algorithms. Behavior estimation aims at estimating the policy with which training data are generated. In particular, this work considers a scenario where the data are collected from multiple sources. In this case, neglecting data heterogeneity, existing approaches for behavior estimation suffers from behavior misspecification. To overcome this drawback, the present study proposes a latent variable model to infer a set of policies from data, which allows an agent to use as behavior policy the policy that best describes a particular trajectory. This model provides with a agent fine-grained characterization for multi-source data and helps it overcome behavior misspecification. This work also proposes a learning algorithm for this model and illustrates its practical usage via extending an existing offline RL algorithm. Lastly, with extensive evaluation this work confirms the existence of behavior misspecification and the efficacy of the proposed model.
@inproceedings{behavior_estimate, author = {Zhang, Guoxi and Kashima, Hisashi}, booktitle = {Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence}, location = {Washington, DC, USA}, publisher = {AAAI Press}, title = {Behavior Estimation from Multi-Source Data for Offline Reinforcement Learning}, year = {2023}, } - Estimating Treatment Effects Under Heterogeneous InterferenceXiaofeng Lin, Guoxi Zhang, Xiaotian Lu, Han Bao, Koh Takeuchi, and Hisashi KashimaIn Machine Learning and Knowledge Discovery in Databases: Research Track, 2023
Treatment effect estimation can assist in effective decision-making in e-commerce, medicine, and education. One popular application of this estimation lies in the prediction of the impact of a treatment (e.g., a promotion) on an outcome (e.g., sales) of a particular unit (e.g., an item), known as the individual treatment effect (ITE). In many online applications, the outcome of a unit can be affected by the treatments of other units, as units are often associated, which is referred to as interference. For example, on an online shopping website, sales of an item will be influenced by an advertisement of its co-purchased item. Prior studies have attempted to model interference to estimate ITE accurately, but they often assume a homogeneous interference, i.e., relationships between units only have a single view. However, in real-world applications, interference may be heterogeneous, with multi-view relationships. For instance, the sale of an item is usually affected by the treatment of its co-purchased and co-viewed items. If this heterogeneous interference is not properly modelled, ITE estimation will be inaccurate. Therefore, we propose a novel approach to model heterogeneous interference by developing a new architecture to aggregate information from diverse neighbors. Our proposed method contains a graph neural network that aggregates same-view information, a mechanism that aggregates information from different views, and attention mechanisms. In our experiments on multiple datasets with heterogeneous interference, the proposed method significantly outperformed existing methods for ITE estimation, confirming the importance of modeling heterogeneous interference.
@inproceedings{heterogeneous_interference, author = {Lin, Xiaofeng and Zhang, Guoxi and Lu, Xiaotian and Bao, Han and Takeuchi, Koh and Kashima, Hisashi}, booktitle = {Machine Learning and Knowledge Discovery in Databases: Research Track}, title = {Estimating Treatment Effects Under Heterogeneous Interference}, year = {2023}, pages = {576--592}, publisher = {Springer Nature}, }
2022
- Improving Pairwise Rank Aggregation via Querying for Rank DifferenceGuoxi Zhang, Jiyi Li, and Hisashi KashimaIn Proceedings of the Ninth IEEE International Conference on Data Science and Advanced Analytics, 2022
Pairwise rank aggregation (PRA) aims at learning a ranking from pairwise comparisons between objects that specify relative ordering of objects. The present study proposes the use of rank difference information for PRA, which characterizes the extent winners in paired comparisons beat their opponents. While such information can be effortlessly recognized by annotators, to our knowledge, it has not been utilized for PRA before. The challenge is three-fold: how to solicit such information, how to utilize it in rank aggregation, and how to overcome the noise from heterogeneous annotators. The present study proposes a new query for soliciting information about rank difference from annotators with limited cognitive burden. As prior methods for PRA abounds, an objective is to empower them with information on rank difference. To this end, the present study proposes a conservative learning objective that can be combined with many existing PRA algorithms in a straightforward manner. The third contribution is a new method for PRA called mixture of exponentials (MoE). Annotators from a heterogeneous population might have diverse views concerning rank difference. An annotator might be good at recognizing rank difference only for a subset of items but not the rest. This means that information about rank difference is likely to be perturbed. Unfortunately, such an object-dependent error pattern cannot be modeled with existing approaches. MoE assumes that each annotator uses a mixture of ranking functions in generating answers. The mixture components can capture object-related patterns in data. The present study evaluates the proposals with extensive experiments on both real and synthetic datasets. The results confirm the efficacy of the proposals and shed light on their practical usage.
@inproceedings{rank_diff, author = {Zhang, Guoxi and Li, Jiyi and Kashima, Hisashi}, booktitle = {Proceedings of the Ninth IEEE International Conference on Data Science and Advanced Analytics}, publisher = {IEEE}, title = {Improving Pairwise Rank Aggregation via Querying for Rank Difference}, year = {2022}, }
2018
- On Reducing Dimensionality of Labeled Data EfficientlyGuoxi Zhang, Tomoharu Iwata, and Hisashi KashimaIn Advances in Knowledge Discovery and Data Mining, 2018
We address the problem of reducing dimensionality for labeled data. Our objective is to achieve better class separation in latent space. Existing nonlinear algorithms rely on pairwise distances between data samples, which are generally infeasible to compute or store in the large data limit. In this paper, we propose a parametric nonlinear algorithm that employs a spherical mixture model in the latent space. The proposed algorithm attains grand efficiency in reducing data dimensionality, because it only requires distances between data points and cluster centers. In our experiments, the proposed algorithm achieves up to 44 times better efficiency while maintaining similar efficacy. In practice, it can be used to speedup k-NN classification or visualize data points with their class structure.
@inproceedings{10.1007/978-3-319-93040-4_7, author = {Zhang, Guoxi and Iwata, Tomoharu and Kashima, Hisashi}, booktitle = {Advances in Knowledge Discovery and Data Mining}, location = {Melbourne, Australia}, pages = {77--88}, publisher = {Springer Cham}, title = {On Reducing Dimensionality of Labeled Data Efficiently}, year = {2018}, }
2017
- Robust Multi-view Topic Modeling by Incorporating Detecting AnomaliesGuoxi Zhang, Tomoharu Iwata, and Hisashi KashimaIn Machine Learning and Knowledge Discovery in Databases, 2017
Multi-view text data consist of texts from different sources. For instance, multilingual Wikipedia corpora contain articles in different languages which are created by different group of users. Because multi-view text data are often created in distributed fashion, information from different sources may not be consistent. Such inconsistency introduce noise to analysis of such kind of data. In this paper, we propose a probabilistic topic model for multi-view data, which is robust against noise. The proposed model can also be used for detecting anomalies. In our experiments on Wikipedia data sets, the proposed model is more robust than existing multi-view topic models in terms of held-out perplexity.
@inproceedings{10.1007/978-3-319-71246-8_15, author = {Zhang, Guoxi and Iwata, Tomoharu and Kashima, Hisashi}, booktitle = {Machine Learning and Knowledge Discovery in Databases}, location = {Skopje, Macedonia}, pages = {238--250}, publisher = {Springer Cham}, title = {Robust Multi-view Topic Modeling by Incorporating Detecting Anomalies}, year = {2017}, }